Problem: Depth of Field. I want bokeh and we want correct blurring of both front and back planes.
Now I have some ideas on that. I think at least one good one. But I'd like to see, in the comments (by the way, if you like this blog, read the comments, usually I write more there than in the main post) your ideas for possible approaches.
Some inspiration: rthdribl (correct bokeh, but bad front blur, slow), lost planet dx10 (correct everything, but slow), dofpro (photoshop, non-realtime).
Words (and publications): gathering, scattering, summed area tables, mipmaps, separable filters, push-pull
I have developed something out of my idea. It currently has four "bugs", but only one that I don't know yet how to solve... The following image is really bad, but I'm happy with what it does... I'll tell you more, if you tell me your idea :)
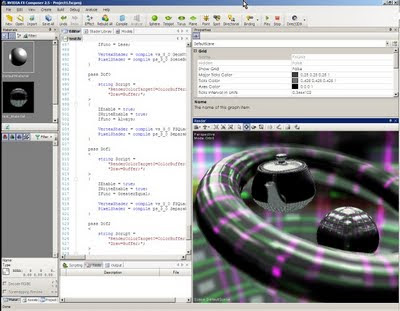
Update: The following is another proof of concept, just to show that achieving correct depth blur is way harder that anchieving good bokeh. In fact you could have a decent looking bokeh even just using separable filters, the first image to the left just takes twice the cost of a normal separable gaussian, and looks almost as good as the pentagonal bokeh from the nonrealtime photoshop lens blur (while the gaussian filter, same size, looks awful)

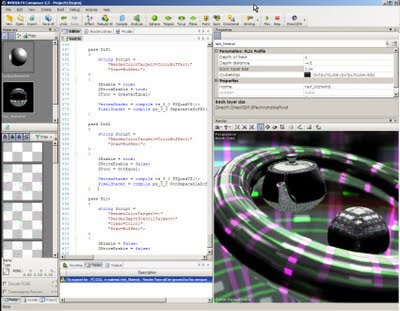
Second Update: I've managed to fix many bugs, now my prototype has a lot less artifacts... I don't know if you can see it, but the DOF correctly bleeds out, even when the object overlaps an in-focus one. Look at the torus, the far side shows clearly the out-bleeding (as you can see an artefact still along the edges...). Now you should be able to see that the very same happens for the near part (less evident as it doesn't have problems, I dunno why, yet), and it doesn't shrink where the torus overlaps the sphere.
Now I have some ideas on that. I think at least one good one. But I'd like to see, in the comments (by the way, if you like this blog, read the comments, usually I write more there than in the main post) your ideas for possible approaches.
Some inspiration: rthdribl (correct bokeh, but bad front blur, slow), lost planet dx10 (correct everything, but slow), dofpro (photoshop, non-realtime).
Words (and publications): gathering, scattering, summed area tables, mipmaps, separable filters, push-pull
I have developed something out of my idea. It currently has four "bugs", but only one that I don't know yet how to solve... The following image is really bad, but I'm happy with what it does... I'll tell you more, if you tell me your idea :)

Update: The following is another proof of concept, just to show that achieving correct depth blur is way harder that anchieving good bokeh. In fact you could have a decent looking bokeh even just using separable filters, the first image to the left just takes twice the cost of a normal separable gaussian, and looks almost as good as the pentagonal bokeh from the nonrealtime photoshop lens blur (while the gaussian filter, same size, looks awful)

Second Update: I've managed to fix many bugs, now my prototype has a lot less artifacts... I don't know if you can see it, but the DOF correctly bleeds out, even when the object overlaps an in-focus one. Look at the torus, the far side shows clearly the out-bleeding (as you can see an artefact still along the edges...). Now you should be able to see that the very same happens for the near part (less evident as it doesn't have problems, I dunno why, yet), and it doesn't shrink where the torus overlaps the sphere.

29 comments:
An idea I've been toying with is to downsample the framebuffer to something like 1/8 to 1/32 width and height and then render a bunch of screen aligned bokeh quads (pretty much circles for a decent lens) at the centre points of the downsampled pixels (maybe with a bit of random jitter) using the colours from the downsampled buffer to tint the quads. Fade these out based on the focal plane depth and the information from the depth buffer.
I don't think this would be particularly good as a general depth of field effect but for scenes where the foreground and background had good separation I think it would give a fairly decent approximation of the kind of extreme bokeh effects you can find if you search Flickr for 'bokeh'. You'd combine it with a standard DoF blur to get the general soft background effect, the well defined bokeh would come from the forward rendering of quads.
Of course this might end up being just as expensive as doing things properly, depends on how low res a downsampled buffer you can get away with and how much fill rate you have.
Ha, I guess I should have read some of the links first, this is obviously not a particularly novel idea :-)
It's not as you noticed, a new idea, but it's interesting combined with a normal DOF blur.
Combining the two things can be tricky, I don't think that the regular grid you will get by downsampling will quite work, I suspect (let's say also that I tried quickly something similar in photoshop :D) it will show...
But still, the idea has its merits. Definitely, a few well placed bokeh particles could improve a DOF. How to well place them? We should identify all the pixels in the scene that have huge DOF blur and possibly also, huge local contrast (those are the areas where bokeh shows more)...
A first start could be, doing it for lights, and other particles that are already in the scene...
I'd say we need a filter to identify the possible candidates, but then to isolate them we would need some sort of 2d stream compaction... Any ideas about that?
I'd had some similar thoughts, I thought about doing a threshold pass to detect particularly bright pixels but then confronted with the stream compaction problem decided that wasn't a very fruitful avenue with current PC hardware. Maybe on the SPUs - I know some studios have been doing post processing on the SPUs and you could probably do a single pass stream compaction / vertex buffer generation for the bokeh particles.
Looking at bokeh photos on Flickr I figured you want to scale rather than fade the bokeh particles based on their distance from the focal plane and skimming through some of the links it seems that is correct - the particles should be scaled according to the circle of confusion size. You could eliminate particles below a certain size during the stream compaction. Adding some jitter to particle positions might help reduce obvious grid artifacts. Bokeh also seem to distort in shape near edges. Adding some random non uniform scaling (perhaps even driven by some edge detection on the depth buffer) might further break up any obvious grid pattern.
Another thought: instead of rendering particles you could do this in a shader using texture bombing (http://http.developer.nvidia.com/GPUGems/gpugems_ch20.html). Something like the procedural circles in that link but with the circle sizes driven by the depth buffer and the colour by the downsampled buffer. It could be right in the shader doing the standard blur so you could do it all in one pass.
I believe this to be a new idea, but I haven't had time to explore it, and thus is not sure if it is at all doable (or would work, to be honest). This is just an idea for the bokeh blurring, and does not in any way extend to the problems of missing object-information of occluded objects.
So, the suggestion is quite simple: Convolve the image in FFT-space. The point of this being that convolution is multiplication in FFT- so the size of the kernel is less important, making the large kernels used for bokeh viable.
GPGPU-FFT used for temporal glare:
http://www.uni-koblenz.de/~ritschel/
As far as I remember, this paper claims bokeh too (but by bruteforce sampling): http://www.nvidia.com/object/nvidia_research_pub_015.html
Getting the blur for foreground (in front of DoF) objects is the most tricky. The simple truth is that you need data that is missing from a rasterising approach that assumes pinhole camera. You can see what I mean from my post at the OpenGL forum:
http://www.opengl.org/discussion_boards/ubbthreads.php?ubb=showflat&Number=263547
The Pixar paper cited uses a 2-pass approach to get the pixels otherwise occluded by the foreground objects. That's what I'm working on and will update it on my blog in a couple days' time.
mattnewport: mhm yes, the stream compaction issue is nasty, but mhm I think it's also what it makes it interesting isn't it? Unfortunately I don't have much time to play with it now, but I'd love to hear from people that did something similar, stream compaction in practice for screen-space effects. I guess in practice you can do something hybrid, having a few passes where you just reduce your buffer, maybe in a smart way (not just downsample the image), and then do a stream compaction... Or maybe experiment with parallel sorting?
You're right about having to scale particles, and also about bokeh changing shape... Actually it would be more than interesting to do a holistic lens effect, that is able to simulate not only DOF but also aberrations (vignetting, spherical aberration, focal plane curvature, coma, chromatic aberrations etc)
About the texture bombing idea. There's something fundamentally right about it. It's very nice, but as is, I don't think it will be successful, because it restricts you with one or so particles per a given square. That's the same problem with using sub sampling instead of stream compaction. Also we're dealing with animated scenes, so I don't think that jittering could be a solution, and it makes having particles per square even a worse problem, because now a particle that crosses a square has to disappear...
You might think of having finer squares, with more than one particle per square. And I'd like you to think about that, because it's becoming to go towards something I think it's interesting (yes, I'm teasing, but I don't want to directly tell what I think and what I tried, because I want to see something different here)...
But more particles mean that you have to blend them together, they will be overlapping... That's not so easy, as they're scattering on different depth layers, you should sort them first.
Mikkel: the image space paper has a very bad DOF implementation, and they actually tell you that in the paper itself so let's discard that.
FFT, that's cool. Actually I've been thinking for a while about wavelets, but I didn't find anything useful there.
How fast can an FFT be on the GPU? In that paper, they don't go into any details about that unfortunately. I just skimmed through it but their timings look weird, I don't understand where the FFT part is.
If the FFT could be fast enough then it starts to be interesting, but the other problem is that I don't think that the convolution is a real problem in DOF implementations. It's true that all the fast ways of convolving an image use a gaussian kernel and not achieve good bokeh, but well, if you consider only the convolution and not the whole DOF effect, it's not too hard (I should post another image about that, maybe you'll see an update of the post soon)...
Anyway, for example http://www.daionet.gr.jp/~masa/rthdribl/ has a decent bokeh (brute force) but it still fails to render good near blur, and that's the hardest part in my opinion.
Rex Guo: very true, you're missing information. But there are plenty of post-processing, zbuffer only effects (non-realtime) that achieve a very good quality. We should at least be able to do something like this, without extra information: http://www.cebas.com/gallery/v/finalDOF/
The examples at http://www.cebas.com/gallery/v/finalDOF/ do look pretty good, but none of them is set up in such a way that shows the worst case scenario. I've done quite a bit of real-world photography myself, and with shots containing lots of bokeh, the translucent blurs of foreground objects contribute a great deal to the overall effect. Of coz it all depends on the requirements of your app. Most games don't need to go to the full extent. So far it looks like a 2-pass approach isn't that bad if you can manage to minimise the amount of overdraw.
I just stumbled upon this paper
Depth-of-Field Rendering with Multiview Synthesis
http://www.mpi-inf.mpg.de/~slee/pub/
Probably too expensive, but maybe it'll spark some ideas :)
That paper basically expands upon the Pixar paper to render a depth-partitioned view frustum into different layers. And that's exactly what I did last week. It's the only way to get the otherwise missing information due to occlusion. However, I haven't figured out a good blending method to composite the front and mid+back layers, as my front layer's blurred region is blurred with black pixels.
Mikko: very nice paper, thanks! Their idea is cool, but you're right, it's not usable per se right now. Also I don't think that you need all those layers... I would rather use depth peeling, even if with it you can't split the scene in non-overlapping ranges, you'll still get only two of them... Depth peeling can be fast, also you know that you don't have to peel the whole scene, but only some edges, so you can use hi-Z to mask the areas you don't need...
rex guo - this is sort of the standard reply, but can't you do that using pre-multiplied alpha?
deadc0de - I agree the convolution is not the main problem, but FFT would allow convolution with ridiculously sized and shaped kernels :) Anyway, not entirely sure about the speed either as I haven't done an implementation - and there's certainly a chance brute-force is faster in many cases.
Mikkel: Sortof... Big kernels would still require big multiplications... Also, you can't mask, the same kernel gets applied everywhere, and masking is central to DOF (as a post-effect). FFT-like decompositions could led us someway, wavelets maybe, but it's not obvious how. Or at least, there's no way I can see of doing DOF with them.
I still have to find the time to read it, but this paper seems nice and in topic.
http://www.eecs.berkeley.edu/Pubs/TechRpts/2009/EECS-2009-54.html
I need to learn japanese :/
http://www.daionet.gr.jp/~masa/archives/CEDEC2009_Anti-DownsizedBufferArtifacts.ppt
Mikkel: looks nice! The first part seems only to be about high-order filtering, but the last looks like a way to simulate bokeh-like filters. Hopefully it's a smart one, I'll ask a japanese colleague of mine to help me with the translation.
Mikkel: mhm so I'm not 100% sure because I didn't get a technical translation, but it seems that what they're doing is the same as the approximation I showed in the second image of this blog post, that is, achieving the hexagonal sampling required for that lens aperture simulation by doing 3 passes of a separable blur (so, that gives 6 in total), in the appropriate directions...
The problem with dof is that it should be a scatter not a gather op. The old ATI example which uses a variable sized circle of confusion just isnt right - it's changing the size of the gathered area not the scattered area and will inherently have artefacts.
The simple way to do a really nice DOF is to use a massive fixed size kernel, and vary the weight by whether and how much the kernel pixel affects the current pixel: is it in z range? is it blurry enough to reach it? Then you'll get correct blurring of things over the top of in focus, and not get those ugly halos.
The problem is it's slow to use a really large blur, which is why I used the SPU to classify and fast-path stuff here (http://research.scee.net/files/presentations/gdc2009/DeferredLightingandPostProcessingonPS3.ppt).
There are other optimisation techniques too of course.
We had a nice DOF in http://www.pouet.net/prod.php?which=53647 i think - works more or less as i described but I used a random rotated (but fixed size) poisson disc. I like noise. :)
One nice thing is that then you can change the shape and weights of the kernel/disc to get bokeh effects. I was happy with a circle shape and it fitted with random rotation nicely, but if you removed the random rotation you could do any shape - you just need enough samples to make it look good.
To get flares to glow out more, you can weight them very highly (or use a very biased HDR input in the first place). The main problem is making it all fast. :)
matt: thanks for the link to the ppt. I took a look at the DoF section and noticed that the case of blurred (out-of-focus) foreground isn't covered. Does your technique deal with this case too?
Description of case:
blur-sharp-blur == foreground-midground-background.
The difficulty with a out-of-focus foreground is that it reveals pixels that are otherwise hidden.
yes, the out of focus foreground works - its approximating a scatter so the foreground pixels get scattered over the in focus ones behind. (we have a sample showing that on ps3 devnet.)
of course its dealing with a framebuffer so it still cant magic up pixels which were not in it.. :) but it works close enough.
matt: nice! That's my idea too, so I'll sprinkle some new hints, for people to think, and come up with their ideas (that hopefully will outperform what I implemented :D)
So there are only a few problems to solve...
- How to do scattering fast? The idea of using SPUs is NEAT, but is it possible to do something similar on the GPU too?
- Scattering is not enough! We have to solve two other problems to get DOF
-- Sorting of the scattered layers! Think about creating DOF with particles (1 per pixel). You alphablend them, so you need to sort!
-- Partial occlusion. Think about raytracing. Real DOF "sees" more behind object silhouettes than a pinhole camera. How to solve/alleviate that?
I implemented scatter as a gather. If you do a large fixed-size gather you can say,
"for each pixel in my gather kernel I will see how that pixel would have scattered to my centre pixel (if it had been done with a scatter)". So that's how I did it - no point sprites and so on, it seemed like it would be far too slow to do that. :) It would be possible to implement by using point sprites and resizing the sprite by it's scatter area, summing them all up etc, but it would cause huge overdraw and be so slow.
Particle DOF can be done a different way of course, by using a more blurred texture when out of focus (mipbias) and a larger particle with lower alpha. Sorting those is doable on GPU - see GPU Gems 2 chapter 46. (or http://directtovideo.wordpress.com/2009/10/06/blunderbuss/ for my take on it :) )
partial occlusion, well, i guess i decided we could live without it, because its possible to make a great dof now in offline renderers using just a post process - id rather copy those. :)
Matt: scatter as gather is the key, but in my experience just accumulating samples and adding them together does not work perfectly. Sorting them and then alpha-blending (based on the spread) is not doable even for a small number of samples (in the shader you could implement only naive n^2 sorting, while gathering) so I ended up with a layering system. I'm surprised that you got good results with scatter-as-gather without any sorting or hack to fake it...
ah - well, i weighted the samples by comparing the depth to the centre pixel as well as the blur "scatter" distance. so only the ones in front of or within a depth threshold of the centre pixel are added.
if you're just summing up all the weighted values and dividing by the weight sum, it's order independent, so no sorting.
Interesting idea about rendering them in order and linear blending them though. I'd be interested to see what the results are and how they differ between the two versions. some screenshots would be interesting indeed.. :)
matt: I'll upload some more images as soon as I have some free time to work on the effect more. Your weighting idea makes much sense to me, probably it's way better than the 'layering' one I'm using right now. How do you sample the scene? Do you spread some random samples in a circle? At the moment I cheat a lot, I do a separable, two pass blur for all the areas that do not have a big depth variance (I detect them during those two passes too), and then a brutal non separable filter pass for the ones that were not covered by the separable pass. I use the ZBuffer to mask out what should be computed in the third pass, but I didn't verify that the hi-z is working, I'm not 100% sure about it because I write the depth per fragment in the separable blur passes... I've got still lots of work to do on this idea.
On PS3 i used that same approach as you - using tiles on the SPU to find what needed a brute force blur and what could use a simple blur. I used to do it on PC too - downsample and min/max the depth buffer until it's one pixel per 16x16 tile, then render one quad per tile use a vertex texture fetch on the vertex shader to decide what to use per tile. (cull the tiles that are not using the current shader pass.)
but on PC now I just use a load of random jittered samples generated in a circle, and I rotate that circle using a random angle from a texture per pixel. swaps noise for sample count basically. :) it means i can use shapes other than circles if I want too :)
Post a Comment