Introduction
Now, if you've been following my blog for a while, you might have noticed that I hate C++ almost as much as I love rapid prototyping, live-editing languages. Wolfram's Mathematica is one of the finest of such tools I've found so far. It might sound surprising as Mathematica's mostly known as a computer algebra system, performing symbolic manipulations that are arguably not the bread and butter of the realtime rendering engineer, but deep down everything boils down to a Lisp-like language with a twist, as it allows different representations of the parse tree (i.e. plain code, mathematical notation, editable widgets and even inline graphics). All of this is coupled with one of the most powerful mathematical and numerical libraries available, with the symbolical math functionality "helping" the numerical one (automatic algorithm selection, generation of derivatives and so on), and topped with a very good visualization system and amazing documentation.
Sounds cool right? Let's start using it then!
Preintegrated Skin Shading
I've been following Eric Penner's Preintegrated Skin Shading for more than a year now. We were colleagues at EA Canada, but we never ended up on the same project and being both interested in graphics research, we ended up having independently discovering a few of the same ideas while working at our project. While Eric was preparing his talk I was trying to help by finding a good analytic approximation for his integral. Unfortunately this work came too late and couldn't be included in the Siggraph talk (Eric lists it as "future development" possibility) so I'm writing this now to complement his work and as a primer to show Mathematica's usefulness in our line of business.
Mathematica's crash course
When you start up Mathematica's interface you'll get prompted to create a new notebook. A notebook is a handy document where you can mix Mathematica's expressions with normal text and graphics, a sort of "active" wordprocessor.
Everything you enter will go in what Mathematica calls a "cell", by default cells are of "input" type, that means ready to accept expressions. Other kind of cells are not "active" and won't be evaluated when asked to process the entire notebook.
When you want to evaluate the contents of a cell you can press shift-enter in it. That will cause its text to go through the Mathematica kernel, and any output generated by it will be shown underneath, in some output cells grouped together with the input one. Expressions terminated with a semicolon won't generate output (it will be suppressed) which is useful to avoid to spam the notebook with intermediate results which don't require checking.
A nifty thing is that expressions can be entered in various formats, Mathematica supports different notations for the same syntax trees. The cool thing is that you can even ask the interface to convert a given cell in one of the formats, so you can get all your expression in a "programmer's" notation and then have them converted into mathematical formulas ("TraditionalForm") without needing to use complex shortcuts to write everything in the mathematical notation.
Ok let's get started now. We'll need to use the skin diffusion profile of d'Eon and Luebke that is expressed as a sum of gaussians with some given coefficients. We start by defining a couple of lists with these coefficients. List literals in Mathematica are entered using curly braces, so we can write and evaluate the following:
ScatterCoeffs = {0.0064, 0.0484, 0.187, 0.567, 1.99, 7.41}*Sqrt[2]
ScatterColors = {{0.233, 0.455, 0.649}, {0.1, 0.336, 0.344}, {0.118, 0.198, 0}, {0.113, 0.007, 0.007}, {0.358, 0.004, 0}, {0.078, 0, 0}}
Note how the output of the first assignment should already have performed the multiply by 1.414. Using the equal operator in Mathematica forces the evaluation of the expression on the right before assigning it to the variable.
If you squinted you should have noticed already the Sqrt[2] in the previous expression. Function arguments in Mathematica are passed in square brackets, and all Mathematica's built-in functions start with an upper case.
As an exercise, let's now define a Gaussian function manually, instead of relying on Mathematica's internal NormalDistribution:
GaussianFn[var_, x_] := 1/Sqrt[2*Pi*var]*Exp[-(x*x)/(2*var)]
Now, as you evaluate this, you should notice a few things. First of all, it generates no output, the := operator is a delayed assignment, it will evaluate the expression only when needed, and not beforehand (similar to a list quote). Second, that function's input parameters are post-pended with a underscore.
In Mathematica, functions are fundamentally expressions with delayed evaluation, when they are invoked the parameter values are substituted into the expression and then the result is evaluated.
This concept is important, also because being a computer algebra system, Mathematica is all about expressions (see "FullForm" in the documentation), and in fact we could have literally defined the same GaussianFn by performing a delayed replacement (using ReplaceAll, or its shortcut /. note that in Mathematica most basic functional operators infix notations as well) into an expression, like this:
GaussianExpr = 1/Sqrt[2*Pi*var]*Exp[-(x*x)/(2*var)]
GaussianFn[p1_,p2_] := GaussianExpr /. {x->p1, var->p2}
GaussianFn[1,0.5] (* evaluate the function, to prove it works *)
Or as a function object, which won't require a delayed assignment as the function object itself will delay the evaluation of its expression:
GaussianFn[p1_,p2_] = Function[{p1,p2},GaussianExpr/.{x->p1, var->p2}]
GaussianFn[1,0.5]
Got that? Probably not, but all should be clear if you as we go, also try things out and have a look at the excellent online documentation that ships with the program.
Let's define now our last helper expression, and then we will delve into Eric's model and how to fit a simplified function to it.
This is the scattering function, it takes a variable between zero and one and as we don't want to deal with computations in the RGB space which would make visualization of all the functions quite more complex, we pass an index between one and three (lists are one-based in Mathematica) that will decide which channel we're using. We will then need to repeat the fitting for every channel. As I wrote, Mathematica is a lisp-like functional programming environment, so we'll often work with lists and list operations:
ScatterFn[x_, rgb_] := Apply[Plus, Table[GaussianFn[var, x], {var, ScatterCoeffs}]*ScatterColors][[rgb]]
In this case the Table function evaluates GaussianFn multiple times generating a list. Each time it will replace the variable "var" with one of the entries in the "ScatterCoeffs" list (note that the other variable, x, will be replaced as it's one of the arguments of ScatterFn, so no "free variable" is left and we should expect to get a list of numbers out of the evaluation). It then multiplies element-wise the list with the ScatterColors one and it applies to the list the "Plus" operator (note that we could have used the infix version "fn @@ expr" as well), thus summing all the elements. We'll then have a single, three-component result (as ScatterColors is a list of three-elements vectors), and we take the "rgb" indexed one out of it (double square brakets is the list indexing operator).
Integrating Skin Scattering
The key idea in Eric's work is that the subsurface scattering in the skin depends on a neighborhood of the shaded point, if we don't account for lighting discontinuities caused by shadows (which are handled separately). We can then approximate this neighborhood using the surface curvature, and pre-integrate the scattering on a sphere (circle, really) of the same curvature. It then generate a two-dimensional texture based on the curvature and normal dot light with the results of this precomputation. We are going to try to fit a simple expression that we can compute in realtime to avoid having to use the texture.
Let's now express this two-dimensional function in Mathematica, following the expression that you can find in Eric's paper:
(* This is the function defined with integrals, as in the paper *)
DiffuseLight[\[Theta]_,r_,rgb_]:=NIntegrate[Clip[Cos[\[Theta]+x], 0,1}]*ScatterFn[Abs[2*r*Sin[x/2]],rgb],{x,-Pi,Pi}]
DiffuseWeight[r_,rgb_]:=NIntegrate[ScatterFn[Abs[2*r*Sin[x/2]],rgb],{x,-Pi,Pi}]
DiffuseIntegral[\[Theta]_,r_,rgb_]:=DiffuseLight[\[Theta],r,rgb]/DiffuseWeight[r,rgb]
This is pretty simple stuff. We're going to generate samples out of these functions (like Eric's precomputed texture) to then compute a fit, so I directly used the numerical integration (NIntegrate) instead of entering it as a mathematical expression and then asking the numerical approximation of it (N[expr] in Mathematica).
Notice the \[Theta], these were entered as "esc" theta "esc" which is one of the ways of adding symbols in Mathematica's expressions (in this case, the Greek letter theta). These expressions are more readable if pasted in Mathematica and converted into StandardForm.
If you are on a slower computer you can tweak the precision parameters of the NIntegrate or replace it with a NSum, as Eric does in his texture-generator shader:
(* This is a bit faster to evaluate, it's a translation of the code used to generate the lookup table, using an evenly spaced sum instead of NIntegrate *)
DiffuseWeight2[r_,rgb_]:=NSum[ScatterFn[Abs[2*r*Sin[x/2]],rgb],{x,-Pi,Pi,2*Pi/20}]
DiffuseLight2[\[Theta]_,r_,rgb_]:=NSum[Clip[Cos[\[Theta]+x],{0,1}]*ScatterFn[Abs[2*r*Sin[x/2]],rgb],{x,-Pi,Pi,2*Pi/20}]
DiffuseIntegral2[\[Theta]_,r_,rgb_]:=DiffuseLight2[\[Theta],r,rgb]/DiffuseWeight2[r,rgb]
Sampling the function
Let's generate now a table of data to be used for the numerical fitting. That has to be in the form { {input0, input1...., output}, ... }. We will use the Table function again for that, the expression that will be evaluated at each element of the table is the list literal {angle, radius, DiffuseIntegral[...]} (we could have used the List[...] function as well, instead of the literal) but this time we'll need two ranges, one for the radius and one for the angle.
The Flatten call is needed because Table, when used with two ranges, generates a list of lists (a matrix), while we want a flat list of three-dimensional vectors.
channel = 1; (* 1=red 2=green 3=blur *)
dataThetaRVal = Flatten[Table[{\[Theta], r, DiffuseIntegral[\[Theta], r, channel]}, {\[Theta], 0, Pi, 2*Pi/20}, {r, 0.25, 6, 1/20}], 1];
Finding a fitting function
For the fitting function I also want to check how well it extrapolates. So I will compute the fit over the original sample range, but then plot it over an extended interval to verify how the function looks like outside it.
To do this we could use Mathematica's function plotting operators (and it might even be a smarter choice) but instead let's still work with a plots that operate on lists of samples, ListPlot3D.
To plot over an extended range we define an interval table, dataIntervalExt, that's because I want to do these extended plots various times so I "save" the sample inputs and then apply them to different functions.
The first time I use this is to generate a graph of how the lambert lighting model would look like. Using Mathematica's functional programming primitives I define an inline function that maps from x (that will be an element of dataIntervalExt, so a two-dimensional input vector) to a list {first of x, second of x, LambertFn[first of x - that is, the angle]} using the function symbol (in Mathematica it will look like "|->"), then I map this function to every element of dataIntervalExt using the inline /@ map.
Notice how the cosGraph plot is hidden by closing the expression with a semicolon, then the Show[...] function will combine the two plots into a single output.
dataIntervalExt = Flatten[Table[{\[Theta], r}, {\[Theta], 0, Pi, 2*Pi/20}, {r, 0, 12, 1/20}], 1];
dataGraph = ListPlot3D[dataThetaRVal, InterpolationOrder -> 3]
cosGraph = ListPlot3D[(x \[Function] {First[x], Last[x], Clip[Cos[First[x]], {0, 1}]}) /@ dataIntervalExt];
Show[dataGraph, cosGraph]
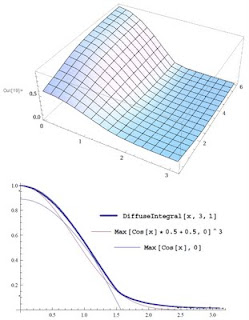 |
| dataGraph and the combined 2d plots |
In order to find a suitable fitting function, I start looking at a graph of some slices slice, fixing a reasonable radius. If the first argument of Plot is a list of functions instead of a single one, it will overlay the plots of all the functions in the list on the same graph. Show does something similar but with any unrelated plots.
plotIn2d = Plot[DiffuseIntegral[x, 3, 1], {x, 0, Pi}]
(* This will generate a graph with three slices and the Lambert's clamped cos *)
Plot[{DiffuseIntegral[x,1,1], DiffuseIntegral[x,3,1], DiffuseIntegral[x,6,1], Max[Cos[x],0]}, {x, 0, Pi}]
I then make some hypothesis and plot a test function against the slice to visually see if it might fit:
(* We have to find a function of cos\[Theta] which could look similar to the DiffuseIntegral*)
Show[Plot[{Max[Cos[x], 0], Max[Cos[x]*0.5 + 0.5, 0]^3}, {x, 0, Pi}], plotIn2d]
Optimizing fitting parameters
Now we can define a function with a number of free parameters, and ask Mathematica to find a fit, a set of parameters that minimizes the distance between the function and the sample set. NonlinearModelFit is used here, that is a slightly more controllable variant of FindFit. This will take quite some time as the function to fit is quite non linear (due to the Max and Clamps).
A word on the function I've selected here and why. I'm sure something better can be done, this is not much more than a simple test, but my reasoning here, after visually inspecting the function to approximate, is that the dependency on the radius is rather simple, while the shape that is dependent on the angle is quite complex.
That's why I started plotting the function in two dimensional graphs that are slices with a fixed radius. Once I've found a possible function that could approximate that with some free parameters, I've modeled the dependency on the radius of these parameters as simple linear equations.
Also I wanted the function to become Lambertian for large radiuses, and I did that by literally having part of the fitting function be a linear interpolation towards the cosine. This constraint is questionable probably for many applications you could just clamp the radius that you will use in a given range, and care only about finding a good fit in that range.
(* Let's find the fit now, first we have to define a parametric function, the fitting process will optimize the parameters to minimize the error *)
(* piecewise linear models... *)
(* fitFunction[\[Theta]_,r_] := Max[Cos[\[Theta]] * Min[(a0*r+a1),1] + Max[(a2*r+a3),0],0] *)
(* fitFunction[\[Theta]_,r_] := Max[Max[Cos[\[Theta]] * Min[(a0*r+a1),1] + Max[(a2*r+a3),0],0], Max[Cos[\[Theta]] * Min[(a4*r+a5),1] + Max[(a6*r+a7),0],0]] *)
(* nonlinear models... *)
(* fitFunction[\[Theta]_,r_] := (Cos[\[Theta]]*(a0*r+a1) + (a2*r+a3))^3 *)
fitFunction[\[Theta]_, r_] := (Cos[\[Theta]]*(a0*r + a1) + (a2*r + a3))^3 * Clip[a4*r + a5, {0, 1}] + Max[Cos[\[Theta]], 0] * (1 - Clip[a4*r + a5, {0, 1}])
fitting = NonlinearModelFit[dataThetaRVal, fitFunction[\[Theta], r], {a0, a1, a2, a3, a4, a5, a6, a7}, {\[Theta], r}, Method -> NMinimize (* We need to use NMinimize for non-smooth models *)]
fitParams = fitting["BestFitParameters"]
Plus @@ Abs /@ fitting["FitResiduals"] (* Print the sum of residuals *)
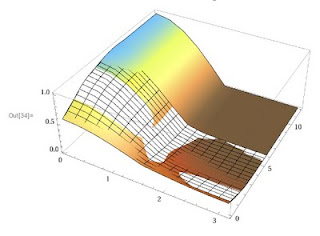 |
| Original function and fitted one, plotted at an extended range to show extrapolation to Cos(theta) |
We can now plot the fitted function and overlay it with the original one for a visual comparison. In order to use the fit we've found, we just replace the parameters we got from the NonlinearModelFit into the original fitFunction using the /. operator.
(* We plot the fit function over dataIntervalExt to check that it extrapolates well *)
dataFit = (x \[Function] {First[x], Last[x], fitFunction[First[x], Last[x]] /. fitParams}) /@ dataIntervalExt;
fitGraph = ListPlot3D[dataFit, InterpolationOrder -> 3, ColorFunction -> "SouthwestColors", Mesh -> None];
Show[fitGraph, cosGraph]
Show[fitGraph, dataGraph]
We can do much more, but this should be a good starting point. I've uploaded a PDF of the whole Mathematica notebook on ScribD here. Enjoy!
P.S. I'd bet everything here could be made ten times faster by applying these suggestions... Left to the reader :)
P.S. You might want to find some better example of Mathematica's goodness than my lame test code. You could start here or here. Also, for Italians only, I've found on Issuu an entire collection of McMicrocomputer magazines, by ADP! Incredible not only for its nostalgia value but also for all the Mathematica's articles by Francesco Romani that showed me more than ten years ago the power and beauty of this software and of maths in general.





