The following doesn't work (yet), but I wanted to write something down both to put it to rest for now, as I prepare for GDC, and perhaps to show the application of some of the ideas I recently wrote about here.
A bit of context. Occlusion culling (visibility determination) per se is far from a solved problem in any setting, but for us (Roblox) it poses a few extra complications:
- We don't allow authoring of "technical details" - so no artist-crafted occluders, cells and portals, and the like.
- Everything might move - even if we can reasonably guess what is dynamic in a scene, anything can be changed by a LuaU script.
- We scale down to very low-power and older devices - albeit this might not necessarily be a hard constraint here, as we could always limit the draw distance on low-end to such degrees that occlusion culling would become less relevant. But it's not ideal, of course.
That said, let's start and find some ideas on how we could solve this problem, by trying to imagine our design landscape and its possible branches.
 |
| Image from https://losslandscape.com/gallery/ |
Real-time "vs" Incremental
I'd say we have a first obvious choice, given the dynamic nature of the world. Either we try to do most of the work in real-time, or we try to incrementally compute and cache some auxiliary data structures, and we'd have then to be prepared to invalidate them when things move.
For the real-time side of things everything (that I can think of) revolves around some form of testing the depth buffer, and the decisions lie in where and when to generate it, and when and where to test it.
Depth could be generated on the GPU and read-back, typically a frame or more late, to be tested on CPU, it could be generated and tested on GPU, if our bottlenecks are not in the command buffer generation (either because we're that fast, or because we're doing GPU-driven rendering), or it could be both generated and tested on CPU, via a software raster. Delving deeper into the details reveals even more choices.
On GPU you could use occlusion queries, predicated rendering, or a "software" implementation (shader) of the same concepts, on CPU you would need to have a heuristic to select a small set of triangles as occluders, make sure the occluders themselves are not occluded by "better" ones and so on.
All of the above, found use in games, so on one hand they are techniques that we know could work, and we could guess the performance implications, upsides, and downsides, and at the same time there is a lot that can still be improved compared to the state of the art... but, improvements at this point probably lie in relatively low-level implementation ideas.
E.g. trying to implement a raster that works "conservatively" in the sense of occlusion culling is still hard (no, it's not the same as conservative triangle rasterization), or trying to write a parallelized raster that still allows doing occlusion tests while updating it, to be able to occlude-the-occluders while rendering them, in the same frame, things of that nature.
As I wanted to explore more things that might reveal "bigger" surprises, I "shelved" this branch...
Let's then switch to thinking about incremental computation and caching.
Caching results or caching data to generate them?
The first thing that comes to mind, honestly, is just to cache the results of our visibility queries. If we had a way to test the visibility of an object, even after the fact, then we could use that to incrementally build a PVS. Divide the world into cells of some sort, maybe divide the cells per viewing direction, and start accumulating the list of invisible objects.
All of this sounds great, and I think the biggest obstacle would be to know when the results are valid. Even offline, computing a PVS from raster visibility is not easy, you are sampling the space (camera positions, angles) and the raster results are not exact themselves, so, you can't know that your data structure is absolutely right, you just trust that you sampled enough that no object was skipped. For an incremental data structure, we'd need to have a notion of "probability" of it being valid.
You can see a pattern here by now, a way of "dividing and conquering" the idea landscape, the more you think about it, the more you find branches and decide which ones to follow, which ones to prune, and which ones to shelve.
Pruning happens either because a branch seems too unlikely to work out, or because it seems obvious enough (perhaps it's already well known or we can guess with low risk) that it does not need to be investigated more deeply (prototyping and so on).
Shelving happens when we think something needs more attention, but we might want to context-switch for a bit to check other areas before sorting out the order of exploration...
So, going a bit further here, I imagined that visibility could be the property of an object - a visibility function over all directions, for each direction the maximum distance at which it would be unoccluded - or the property of the world, i.e. from a given region, what can that region see. The object perspective, even if intriguing, seems a mismatch both in terms of storage and in terms of computation, as it thinks of visibility as a function - which it is, but one that is full of discontinuities that are just hard to encode.
If we think about world, then we can imagine either associating a "validity" score to the PVS cells, associating a probability to the list of visible objects (instead of being binary), or trying to dynamically create cells. We know we could query, after rendering, for a given camera the list of visible objects, so, for an infinitesimal point in 5d space, we can create a perfect PVS. From there we could cast the problem as how to "enlarge" our PVS cells, from infinitesimal points to regions in space.
This to me, seems like a viable idea or at least, one worth exploring in actual algorithms and prototypes. Perhaps there is even some literature about things of this nature I am not aware of. Would be worth some research, so for now, let's shelve it and look elsewhere!
Occluders
Caching results can be also thought of as caching visibility, so the immediate reaction would be to think in terms of occluder generation as the other side of the branch... but it's not necessarily true. In general, in a visibility data structure, we can encode the occluded space, or the opposite, the open space.
We know of a popular technique for the latter, portals, and we can imagine these could be generated with minimal user intervention, as Umbra 3 introduced many years ago the idea of deriving them through scene voxelization.
 |
| Introduction to Occlusion Culling | by Umbra 3D | Medium |
It's realistic to imagine that the process could be made incremental, realistic enough that we will shelve this idea as well...
Thinking about occluders seem also a bit more natural for an incremental algorithm, not a big difference, but if we think of portals, they make sense when most of the scene is occluded (e.g. indoors), as we are starting with no information, we are in the opposite situation, where at first the entire scene is disoccluded, and progressively might start discovering occlusion, but hardly "in the amount" that would make most natural sense to encode with something like portals. There might be other options there, it's definitely not a dead branch, but it feels unlikely enough that we might want to prune it.
Here, is where I started going from "pen and paper" reasoning to some prototypes. I still think the PVS idea that we "shelved" might get here as well, but I chose to get to the next level on occluder generation for now.
From here on the process is still the same, but of course writing code takes more time than rambling about ideas, so we will stay a bit longer on one path before considering switching.
When prototyping I want to think of what the real risks and open questions are, and from there find the shortest path to an answer, hopefully via a proxy. I don't need at all to write code that implements the way I think the idea will work out if I don't need to - a prototype is not a bad/slow/ugly version of the final product, it can be an entirely different thing from which we can nonetheless answer the questions we have.
With this in mind, let's proceed. What are occluders? A simplified version of the scene, that guarantees (or at least tries) to be "inside" the real geometry, i.e. to never occlude surfaces that the real scene would not have occluded.
Obviously, we need a simplified representation, because otherwise solving visibility would be identical to rendering, minus shading, in other words, way too expensive. Also obvious that the guarantee we seek cannot hold in general in a view-independent way, i.e. there's no way to compute a set of simplified occluders for a polygon soup from any point of view, because polygon soups do not have well-defined inside/outside regions.
So, we need to simplify the scene, and either accept some errors or accept that the simplification is view-dependent. How? Let's talk about spaces and data structures. As we are working on geometry, the first instinct would be to somehow do computation on the meshes themselves, in object and world space.
It is also something that I would try to avoid, pruning that entire branch of reasoning, because geometric algorithms are among the hardest things known to mankind, and I personally try to avoid writing them as much as I can. I also don't have much hope for them to be able to scale as the scene complexity increases, to be robust, and so on (albeit I have to say, wizards at Roblox working on our real-time CSG systems have cracked many of these problems, but I'm not them).
World-space versus screen-space makes sense to consider. For data structures, I can imagine point clouds and voxels of some sort to be attractive.
First prototype: Screen-space depth reprojection
Took a looong and winding road to get here, but this is one of the most obvious ideas as CryEngine 3 showed it to be working more than ten years ago.
 |
| Secrets of CryEngine 3 |
I don't want to miscredit this, but I think it was Anton Kaplanyan's work (if I'm wrong let me know and I'll edit), and back then it was dubbed "coverage buffer", albeit I'd discourage the use of the word as it already had a different meaning (the c-buffer is a simpler version of the span-buffer, a way to accelerate software rasterization by avoiding to store a depth value per pixel).
They simply took the scene depth after rendering, downsampled it, and reprojected - by point splatting - from the viewpoint of the next frame's camera. This creates holes, due to disocclusion, due to lack of information at the edges of the frame, and due to gaps between points. CryEngine solved the latter by running a dilation filter, able to eliminate pixel-sized holes, while just accepting that many draws will be false positive due to the other holes - thus not having the best possible performance, but still rendering a correct frame.
 |
| Holes, in red, due to disocclusions and frame edges. |
This is squarely in the realm of real-time solutions though, what are we thinking?
Well, I was wondering if this general idea of having occluders from a camera depthbuffer could be generalized a bit more. First, we could think of generating actual meshes - world-space occluders, from depth-buffer information.
As we said above, these would not be valid from all view directions, but we could associate the generated occluders from a set of views where we think they should hold up.
Second, we could keep things as point clouds and use point splatting, but construct a database from multiple viewpoints so we have more data to render occluder and fill the holes that any single viewpoint would create.
For prototyping, I decided to use Unity, I typically like to mix things up when I write throwaway code, and I know Unity enough that I could see a path to implement things there. I started by capturing the camera depth buffer, downsampling, and producing a screen-aligned quad-mesh I could displace, effectively like a heightfield. This allowed me to write everything via simple shaders, which is handy due to Unity's hot reloading.

 |
| Test scene, and a naive "shrink-wrap" mesh generated from a given viewpoint |
Clearly, this results in a "shrink-wrap" effect, and the generated mesh will be a terrible occluder from novel viewpoints, so we will want to cut it around discontinuities instead. In the beginning, I thought about doing this by detecting, as I'm downsampling the depth buffer, which tiles can be well approximated by a plane, and which contain "complex" areas that would require multiple planes.
This is a similar reasoning to how hardware depth-buffer compression typically works, but in the end, proved to be silly.
An easier idea is to do an edge-detection pass in screen-space, and then simply observe which tiles contain edges and which do not. For edge detection, I first generated normals from depth (and here I took a digression trying and failing to improve on the state of the art), then did two tests.
 |
| A digression... |
First, if neighboring pixels are close in 3d space, we consider them connected and do not generate an edge. If they are not close, we do a second test by forming a plane with the center pixel and its normal and looking at the point-to-plane distance. This avoids creating edges connected geometry that just happens to be at a glancing angle (high slope) in the current camera view.


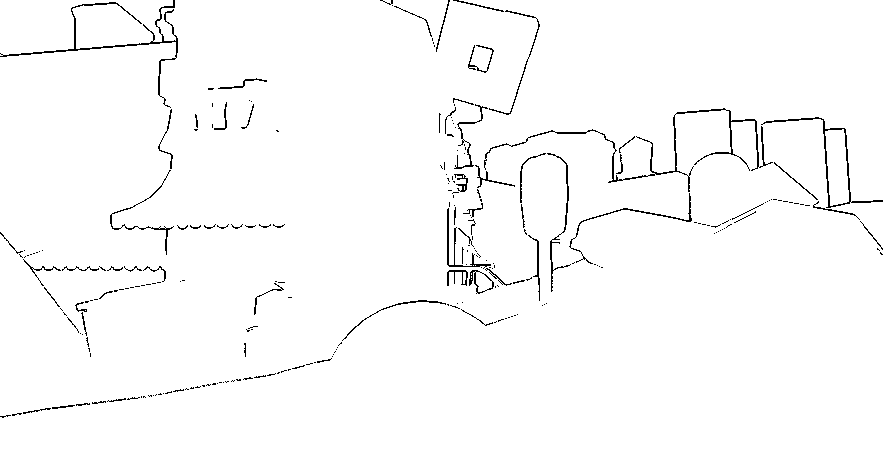 |
| Depth, estimated normals, estimated edge discontinuties. |
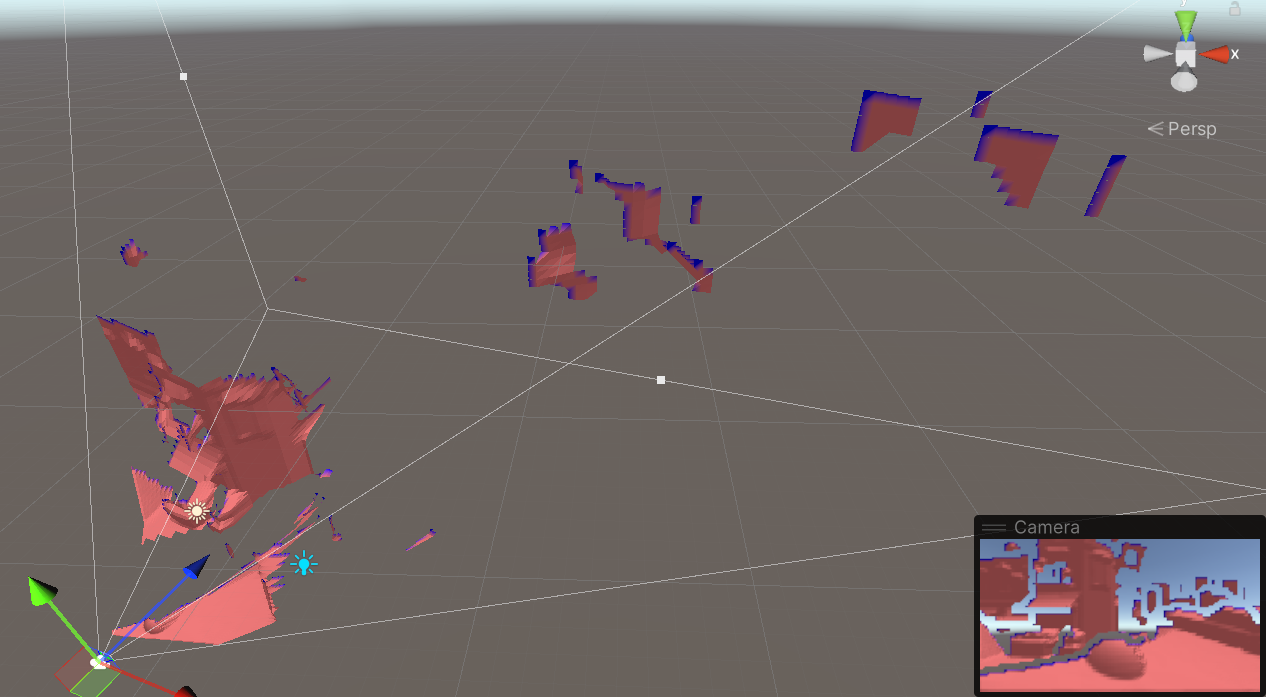
In practice this is overly conservative as it generates large holes, we could instead push the "edge" quads to the farthest depth in the tile, which would hold for many viewpoints, or do something much more sophisticated to actually cut the mesh precisely, instead of relying on just quads. The farthest depth idea is also somewhat related to how small holes are filled in Crytek's algorithm if one squints enough...

What seems interesting, anyhow, is that even with this rudimentary system we can find good, large occluders - and the storage space needed is minimal, we could easily hold hundreds of these small heightfields in memory...
 |
| Combining multiple (three) viewpoints |
So right now what I think would be possible is:
- Keep the last depth and reproject plus close small holes from that, ala Crytek.
- Then try to fill the remaining holes by using data from other viewpoints.
- For each view we can have a bounding hierarchy by just creating min-max depth mips (a pyramid), so we can test the volumes against the current reprojection buffer. And we need only to "stencil" test, to see how much of a hole we could cover and with what point density.
- Rinse and repeat until happy...
- Test visibility the usual way (mip pyramid, software raster of bounding volumes...)
- Lastly, if the current viewpoint was novel enough (position and look-at direction) compared to the ones already in the database, consider adding its downsampled depth to the persistent database.
As all viewpoints are approximate, it's important not to try to merge them with a conventional depthbuffer approach, but to prioritize first the "best" viewpoint (the previous frame's one), and then use the other stored views only to fill holes, prioritizing views closer to the current camera.
If objects move (that we did not exclude from occluder generation), we can intersect their bounding box with the various camera frustums, and either completely evict these points of view from the database, or go down the bounding hierarchy / min-max pyramid and invalidate only certain texels - so dynamic geometry could also be handled.
The idea of generating actual geometry from depth probably also has some merit, especially for regions with simple occlusion like buildings and so on. The naive quad mesh I'm using for visualization could be simplified after displacement to reduce the number of triangles, and the cuts along the edges could be done precisely, instead of on the tiles.
But it doesn't seem worth the time mostly because we would still have very partial occluders with big "holes" along the cuts, and merging real geometry from multiple points of view seems complex - at that point, we'd rather work in world-space, which brings to...
Second prototype: Voxels
Why all the complications about viewpoints and databases, if in the end, we are working with point sets? Could we store these directly in world-space instead? Maybe in a voxel grid?
Of course, we can! In fact, we could even just voxelize the scene in a separate process, incrementally, generating point clouds, signed distance fields, implicit surfaces, and so on... That's all interesting, but for this particular case, as we're working incrementally anyways, using the depth buffer is a particularly good idea.
Going from depth to voxels is trivial, and we are not even limited to using the main camera depth, we could generate an ad-hoc projection from any view, using a subset of the scene objects, and just keep accumulating points / marking voxels.
Incidentally, working on this made me notice an equivalence that I didn't think of before. Storing a binary voxelization is the same as storing a point cloud if we assume (reasonably) that the point coordinates are integers. A point at a given integer x,y,z is equivalent to marking the voxel at x,y,z as occupied, but more interestingly, when you store points you probably want to compress them, and the obvious way to compress would be to cluster them in grid cells, and store grid-local coordinates at a reduced precision. This is exactly equivalent then again to storing binary voxels in a sparse representation.

It is obvious, but it was important to notice for me because for a while I was thinking of how to store things "smartly", maybe allow for a fixed number of points/surfels/planes per grid and find ways to merge when adding new ones, all possible and fun to think about, but binary is so much easier.
In my compute shader, I am a rebel bit-pack without even InterlockedOR because I always wanted to write code with data races that still converge to the correct result!
 |
| As the camera moves (left) the scene voxelization is updated (left) |
If needed, one could then take the binary voxel data and compute from it a coarser representation that encodes planes or SDFs, etc! This made me happy enough that even if it would be cute to figure out other representations, they all went into a shelve-mode.
I spent some time thinking about how to efficiently write a sparse binary voxel, or how to render from it in parallel (load balancing the parallel work), how to render front-to-back if needed, all interesting problems but in practice, not worth yet solving. Shelve!
The main problem with a world-space representation is that the error in screenspace is not bounded, obviously. If we get near the points, we see through them, and they will be arbitrarily spaced apart. We can easily use fewer points farther from the camera, but we have a fixed maximum density.
The solution? Will need another blog post, because this is getting long... and here is where I'm at right now anyways!
I see a few options I want to spend more time on:
1) Draw points as "quads" or ellipsoids etc. This can be done efficiently in parallel for arbitrary sizes, it's similar to tile-based GPU particle rendering.


 |
| From Raw point cloud deferred shading through screen space pyramidal operators (hal.science) - see also marroquim-pbg2007.pdf (ufrj.br) |
3) We could reconstruct a surface for near voxels, either by producing an actual mesh (which we could cache, and optimize) or by raymarching (gives the advantage of being able to stop at first intersection).
We'd still points at a distance, when we know they would be dense enough for simple dilation filters to work, and switch to the more expensive representation only for voxels that are too close to the camera to be treated as points.
 |
| Inspired by MagicaVoxel's binary MC (see here a shadertoy version) - made a hack that could be called "binary sufrace nets". Note that this is at half the resolution of the previous voxel/point clouds images, and still holds up decently. |
No comments:
Post a Comment